Capítulo 9: Interpolación Asistida por Estaciones para Superficies Climáticas Mejoradas (BASIICS)
Resumen

Figura 9-1 El Background-Assisted Station Interpolation for Improved Climate Surfaces (BASIICS) en GeoCLIM facilita la mejora de variables climáticas al ajustar datos de ráster con estaciones locales, entre otras funciones.
Los datos satelitales proporcionan información útil sobre los patrones de variables climáticas (precipitación, temperatura y evapotranspiración). Sin embargo, a veces los datos estimados por satélite pueden contener sesgos e inexactitudes debido al uso incorrecto o limitado de datos de estaciones terrestres durante la calibración. Algunos datos raster también tienen una baja resolución espacial, lo que significa que el tamaño del píxel es demasiado grande para el área de interés. Estos datos podrían mejorarse combinándolos con información de estaciones terrestres utilizando el algoritmo de Background-Assisted Station Interpolation for Improved Climate Surfaces (BASIICS) en GeoCLIM. Ver el icono en el recuadro rojo en la Figura 9-1.
La herramienta BASIICS incluye los siguientes procesos como se muestra en la Figura 9-2:
Fusionar raster/grids climáticas con estaciones (BASIICS).
Validar datos satelitales utilizando valores de estaciones terrestres.
Interpolar solo estaciones.
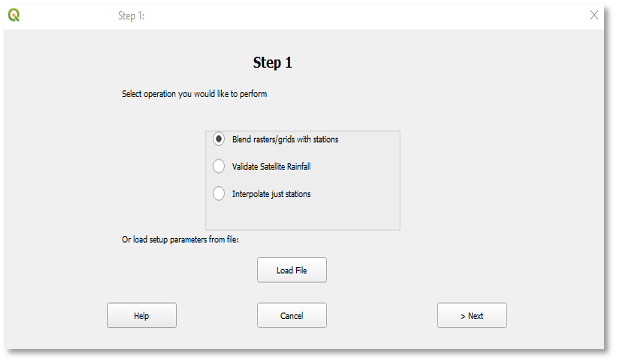
Figura 9-2 Hay tres opciones disponibles en la herramienta BASIICS: (1) fusionar estaciones y datos raster, (2) Validar la precipitación satelital y (3) Interpolar solo estaciones.
Se recomienda seguir el siguiente proceso de tres pasos para producir conjuntos de datos raster mejorados:
Utiliza la función de descarga o importa los conjuntos de datos raster que se desean mejorar, consulta chapter 2.
Utiliza Validate Satellite rainfall para determinar si los datos raster y las estaciones están correlacionados.
Si están correlacionados, combina los dos conjuntos de datos para producir estimaciones mejoradas de lluvia. Guarda la configuración en un archivo para poder usarla más tarde y actualizar la serie temporal de lluvia mejorada.
9.1. Validar la precipitación satelital
La opción de Validar la precipitación basada en satélite te permite evaluar conjuntos de datos en formato raster utilizando puntos en el espacio (por ejemplo, pluviómetros). La validación ayuda a determinar si los dos conjuntos de datos están correlacionados, lo cual ayuda a decidir si se puede usar la opción de fusionar los dos conjuntos de datos para mejorar el raster utilizando los valores de los puntos.
El proceso de validación primero extrae valores de un raster en todas las ubicaciones donde los datos de puntos tienen valores válidos (es decir, valores no faltantes. Los valores faltantes pueden especificarse en las entradas). Los resultados del proceso de validación son: 1) Un shapefile con los puntos que fueron incluidos en el proceso. 2) Un campo raster de los valores interpolados. 3) Una tabla .csv que contiene los valores de las estaciones, el valor del pixel correspondiente junto con información sobre la regresión de mínimos cuadrados entre el valor de los datos observados/in situ en los puntos evaluados y los valores raster extraídos, junto con un valor de R-cuadrado de salida. Una vez que se ha determinado la correlación, entonces los datos raster y de las estaciones pueden mezclarse para producir un conjunto de datos mejorado.
Para validar datos raster, sigue los tres pasos que se indican a continuación:
9.1.1. Paso 1: Selecciona la opción BASIICS
Haz clic en el icono de BASIICS en la barra de herramientas principal de GeoCLIM para abrir el cuadro de diálogo (Paso 1) (Figura 9-1).
Selecciona la opción ■ Validate Satellite Rainfall option. Consulta la Figura 9-2.
Haz clic en el botón > Next para proceder al Paso 2.
9.1.2. Paso 2: Parámetros del conjunto de datos y de la estación
Completa el formulario con la información de los datos raster y de estación. Este formulario está compuesto por 3 secciones (Figura 9-3).
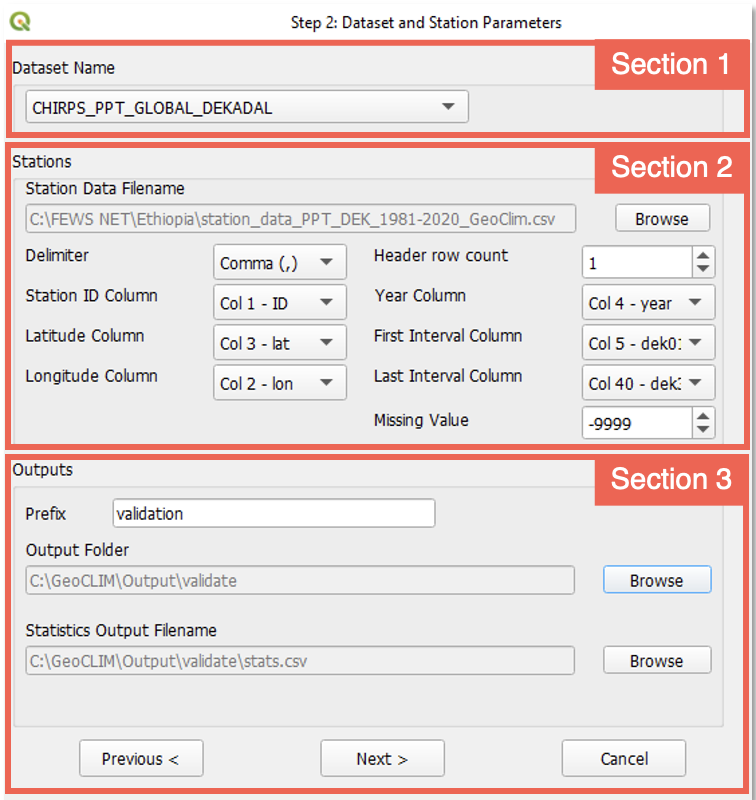
Figura 9-3 El Paso 2 te permite ingresar la información del raster y de la estación para la validación.
9.1.2.1. Sección 1: Nombre del Conjunto de Datos Raster
Esta sección se relaciona con los parámetros de entrada de los datos ráster. Este proceso permite validar conjuntos de datos climáticos que ya han sido registrados en GeoCLIM. Para seleccionar el conjunto de datos climáticos a validar, utilice el menú desplegable Dataset Name ˅.
9.1.2.2. Sección 2: Estaciones
Esta sección se refiere a los parámetros de entrada de la estación.
La herramienta asume que todos los datos de las estaciones están en un único archivo CSV. Navega para seleccionar el archivo que contiene los datos de las estaciones. Ver un ejemplo en la Figura 9-4 del formato del archivo. Para obtener más información sobre el formato de la tabla y otros tipos de archivos en GeoCLIM, consulta el capítulo 3 Gestión de Datos.
Después de seleccionar el archivo de estaciones, la herramienta identifica la fila de encabezado y completa automáticamente los campos. Realiza los cambios necesarios para asegurarte de que todos los campos tengan la especificación correcta. Una vez que todas las especificaciones están definidas, pasa a la sección 3.

Figura 9-4 La tabla CSV con los datos de las estaciones debe contener un ID de estación, longitud, latitud, año y una columna para cada pentada, decadia o mes.
9.1.2.3. Sección 3: Salidas
Especifica el prefijo de salida para todos los archivos raster creados con la interpolación de las estaciones de entrada.
Selecciona la carpeta de salida.
Selecciona el nombre del archivo de salida que contiene las estadísticas.
9.1.3. Paso 3: Parámetros de fecha
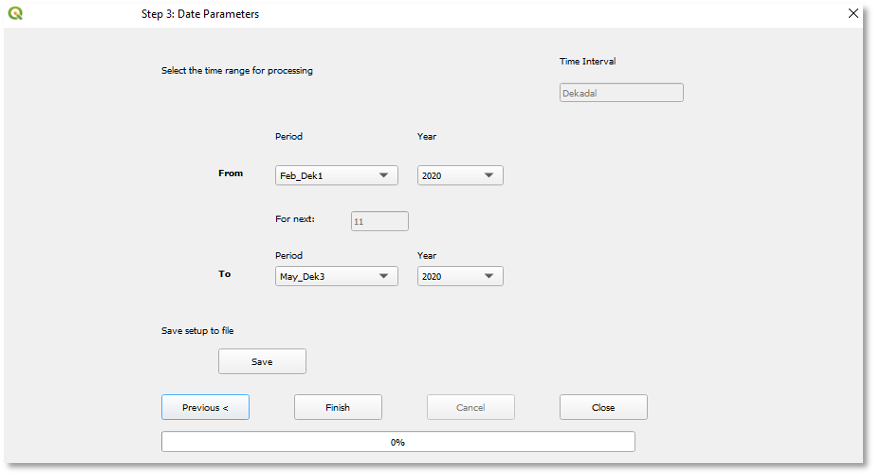
Figura 9-5 El Paso 3 te permite seleccionar un período para validar y guardar la configuración para usarla posteriormente.
Selecciona el período de validación de la siguiente manera (consulta la Figura 9-5).
El intervalo de tiempo (por ejemplo, mes, decadia o pentadas) del conjunto de datos raster seleccionado se muestra automáticamente. Selecciona el rango de tiempo "Desde" y "Hasta" de los datos raster a validar. El período de tiempo y el intervalo de tiempo se basan en la definición del conjunto de datos climáticos seleccionado (ver capítulo 2 para cómo definir un conjunto de datos). En este ejemplo estamos utilizando decadias, consulta la Figura 9-5. Estamos validando desde (Feb decadia 01) hasta (mayo decadia 03), 2020.
Guarda la configuración. En este paso, puedes guardar los ajustes de validación para poder abrirlos desde el paso 1, editarlos y reutilizarlos.
Haz clic en el botón Finalizar para ejecutar el proceso.
Salidas: El proceso de validación crea las siguientes salidas:
Un archivo shapefile, para cada período, que contiene todas las estaciones que se utilizaron en el proceso.
Un campo interpolado, para cada período, utilizando el proceso de IDW (Ponderación Inversa de la Distancia). Consulta la Figura 9-6.
Un gráfico de dispersión que muestra los valores del campo de precipitación satelital frente a los valores de las estaciones (Figura 9-6a).
Un archivo CSV con columnas que contienen los metadatos para cada estación junto con el valor de la estación, el valor del píxel correspondiente y el valor interpolado en el punto donde está la estación. Estos valores interpolados se producen para mejorar la comparabilidad entre los datos en raster y los datos de las estaciones. El archivo CSV incluye estadísticas que muestran la correlación entre el campo de precipitación y los datos de las estaciones (Figura 9-6c).
Estas salidas proporcionan la base para decidir si es apropiado combinar los datos de las estaciones y los conjuntos de datos raster.
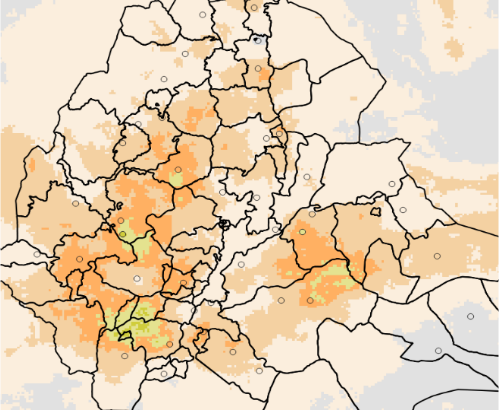
Figura 9-6a El proceso de validación produce un campo de interpolación junto con un shapefile que contiene todos los puntos incluidos.
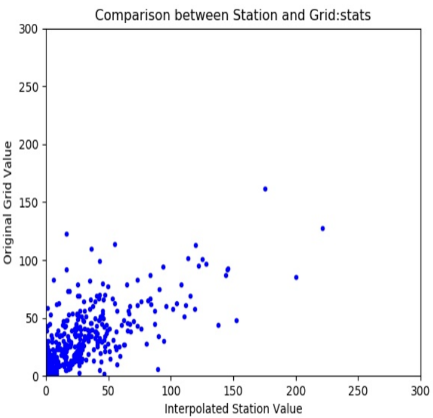
Figura 9-6b Diagrama de dispersión del valor interpolado de la estación en X y el valor raster (CHIRPS) en Y.
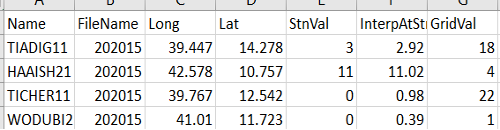
Figura 9-6c Archivo de texto que incluye una lista del valor de la estación y su correspondiente valor raster para cada fecha, junto con estadísticas que describen su relación.
9.2. Fusión de datos rasters con estaciones (BASIICS)
El algoritmo de fusión es una metodología diseñada para combinar valores de estaciones, como pluviómetros, con datos ráster, como estimaciones basadas en satélites, para producir un conjunto de datos en formato raster mejorados. El algoritmo combina los datos de puntos espacialmente distribuidos con datos de raster espacialmente continuos interpolando las diferencias (proporciones y anomalías) entre el punto y el valor de la cuadrícula, donde se ubican estos dos datos. La combinación se realiza utilizando un método de ponderación de distancia inversa (IDW) modificado, que utiliza algunos conceptos del método de interpolación kriging, particularmente el kriging simple y ordinario. La técnica es similar en principio a la técnica SEDI que se origina en el Proyecto Regional de Percepción Remota de la Comunidad de Desarrollo de África Austral (SADC)/FAO, desarrollado por Peter Hoefsloot.
9.2.1. Datos de entrada para la fusión
El programa espera dos tipos de datos como se describe a continuación:
Un conjunto de datos puntuales con valores en ubicaciones distribuidas en el espacio (ejemplo: pluviómetros).
Un conjunto de datos de cuadrícula con valores que varían continuamente en el espacio (por ejemplo, una cuadrícula de estimación de precipitaciones basada en satélites o un promedio climático). Para que el algoritmo se utilice de forma eficaz, los dos conjuntos de datos deben estar correlacionados.
9.2.2. El proceso
Paso 1. Extraer valores de los datos raster, en este ejemplo usamos los datos CHIRPS, en todas las ubicaciones donde los datos de puntos tengan valores válidos (el usuario puede especificar los valores faltantes). Esto produce un conjunto de datos comparable de valores del pixel, en las ubicaciones donde caen los puntos, que se pueden comparar directamente con los valores de los puntos; consulte la sección 9.2 para la validación.
Paso 2. Corrección multiplicativa: Se calcula una relación entre los valores de estación y del pixel; Estas relaciones se interpolan utilizando un método IDW modificado, dando una distancia efectiva máxima a cada estación. Una vez alcanzada la distancia máxima efectiva, la capa interpolada toma el valor de 1 (Figura 9-7). La capa de lluvia original se multiplica por la capa de relación interpolada. Los píxeles dentro de una distancia máxima efectiva de una estación ajustan el valor ráster en función de la proporción, los píxeles fuera de la influencia de una estación, que tomó el valor de 1, toman el valor de la capa ráster original.
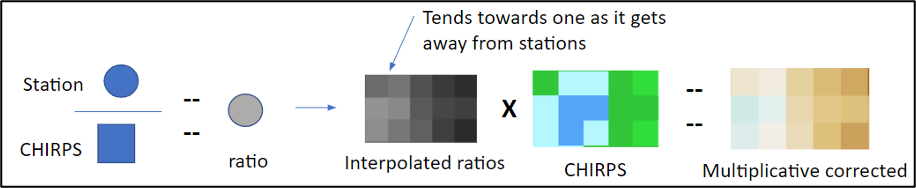
Figura 9-7 La primera parte del proceso de fusión es una corrección multiplicativa basada en la relación entre la estación y los valores ráster.
Paso 3. Corrección aditiva: La anomalía entre la estación y el ráster original se calcula en cada punto. Las anomalías se interpolan utilizando un método IDW modificado, dando una distancia efectiva máxima a cada estación. Una vez alcanzada la distancia máxima efectiva, la capa interpolada toma el valor de 0.
Paso 4. Las anomalías interpoladas se agregan a la capa de lluvia corregida multiplicativa del paso 2 para obtener la Estimación de lluvia mejorada (Improved Rainfall Estimate, IRE, en ingles), ver Figura 9-8.
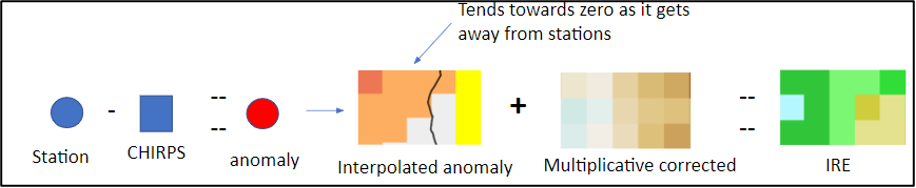
Figura 9-8 Se realiza una segunda corrección basada en las anomalías entre la estación y los valores ráster originales.
9.3. Cómo crear estimaciones de lluvia mejoradas
9.3.1. Paso 1: Selecciona la opción BASIICS
Haga clic en el botón BASIICS de la barra de herramientas principal de GeoCLIM. Consulte la Figura 9-1.
Seleccione la opción ■ Blend rasters/grids with stations. En este punto, puede hacer clic en el botón Load File para cargar la configuración previamente guardada o hacer clic en el botón > Next para iniciar un nuevo proceso de fusión. Consulte la Figura 9-9.
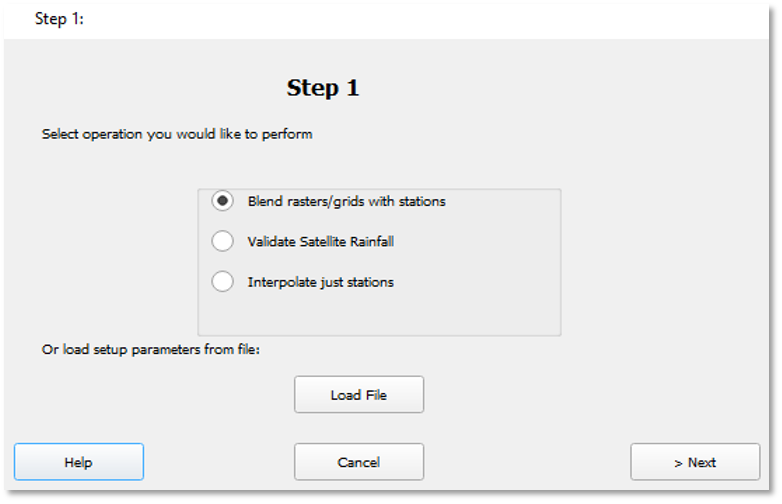
Figura 9-9 Seleccione la opción Blend raster/Grid con estaciones.
9.3.2. Paso 2: Conjunto de datos y parámetros de estaciones
Complete el formulario con información de datos ráster y de estación. Este formulario está formado por 5 secciones (Figura 9-10).
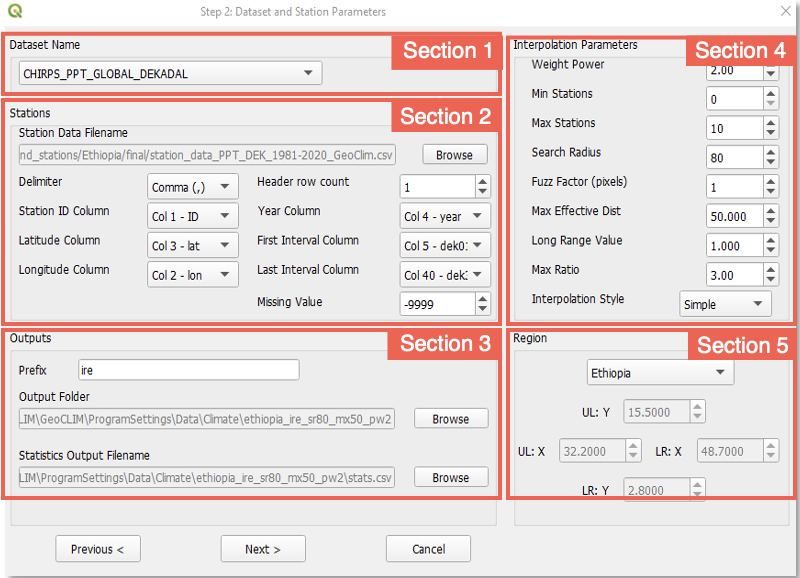
Figura 9-10 El paso 3 del proceso de combinación requiere información sobre los datos ráster, las estaciones, la ubicación de salida, los parámetros de interpolación y el dominio geográfico.
9.3.2.1. Sección 1: Nombre de los datos raster
Esta sección se relaciona con los parámetros de entrada de los datos ráster. Este proceso permite mejorar los conjuntos de datos climáticos que ya han sido registrados en GeoCLIM. Para seleccionar el conjunto de datos climáticos que se utilizará en el proceso, utilice el menú desplegable Dataset Name ˅. En este ejemplo vamos a combinar datos de decadias de CHIRPS con estaciones.
9.3.2.2. Sección 2: Estaciones
Esta sección se relaciona con los parámetros de entrada de las estaciones.
La herramienta asume que todos los datos de estaciones están en un único archivo csv. Seleccione el archivo que contiene las estaciones. Vea un ejemplo en la Figura 9-11 del formato del archivo. El orden de las columnas no es importante, pero debe incluir lo siguiente:
Un ID de identificador de estación único, en una sola columna.
Una columna con longitud en grados decimales.
Una columna con latitud en grados decimales.
Una columna con valor de año (yyyy).
Una serie de columnas consecutivas para el número de períodos (72 para pentadas, 36 para decadias o 12 para meses).
Cualquier dato faltante debe completarse con un único Valor faltante, por ejemplo (-9999).

Figura 9-11 La tabla CSV con datos de la estación debe contener un ID de estación, longitud, latitud, año y una columna para cada pentada, decadia o mes.
Una vez que selecciona el archivo de estaciones, la herramienta identifica la fila del encabezado y completa automáticamente la mayoría de los campos. Realice los cambios necesarios para garantizar que todos los campos tengan la especificación correcta.
9.3.2.3. Sección 3 – Resultados
En la tercera sección, puede especificar el directorio de salida donde guardar los productos mejorados. En este punto, tiene dos opciones: (1) crear un nuevo conjunto de datos o (2) actualizar un conjunto de datos existente.
Crear un nuevo conjunto de datos: Esta primera opción le permite crear un nuevo conjunto de datos en el formato correcto para que funcione con las funciones de GeoCLIM; por ejemplo, está fusionando, por primera vez, sus estaciones con los datos históricos de CHIRPS o CHIRP y desea crear un nuevo conjunto de datos a partir de los resultados. Para hacer esto:
Proporcione un prefijo para los archivos de salida.
Navegue hasta el repositorio de datos de GeoCLIM. Por ejemplo:
X:~\fews_tools_WS\ProgramSettings\Data\Climate\new_dataset donde X:~ es la ruta al espacio de trabajo fews_tools_WS.
La ruta en el campo Statistics Output Filename cambia automáticamente cuando define el directorio de salida, ver sección 3 en la figura 9-10.
Asegúrese de completar los campos de las secciones 4 y 5 antes de continuar. (Consulte las secciones 4 y 5 para una explicación completa de los parámetros).
Haga clic en Next después de completar todos los campos.
Aparece un cuadro de diálogo con la pregunta ‘Do you want to create a new dataset from outputs?’ si desea crear un nuevo conjunto de datos.
Haga clic en Yes. si es la primera vez que va a crear los datos.
Ingrese un nuevo nombre sin espacios.
Seleccione el tipo de datos.
Seleccione la extensión de los datos. Si su región está fuera de África o América Central, seleccione global.
Haga clic en OK para pasar al Paso 3.
Actualizar un conjunto de datos existente: la segunda opción es agregar el producto del proceso a un conjunto de datos existente. Por ejemplo, está fusionanado la última decadia de CHIRPS con las estaciones y actualizando la serie temporal que creó anteriormente.
En el campo Output folder, busque el directorio existente
X:~\fews_tools_WS\ProgramSettings\Data\Climate\datos_existentesdonde X:~ es la carpeta que contiene el espacio de trabajo.La ruta en el campo Statistics Output Filename, nombre de archivo de salida de estadísticas, cambia automáticamente cuando especifica el directorio de salida.
Asegúrese de completar los campos de las secciones 4 y 5 antes de continuar. (Consulte las secciones 4 y 5 para una explicación completa de los parámetros).
Haga clic en Next después de completar todos los campos.
Aparece un cuadro de diálogo preguntando Do you want to create a new dataset from outputs?
Haga clic en No para pasar al Paso 3.
9.3.2.4. Sección 4 - El proceso de fusión - Parámetros de interpolación
El programa ofrece un conjunto de opciones para ajustar los parámetros de la interpolación (Figura 9-12).
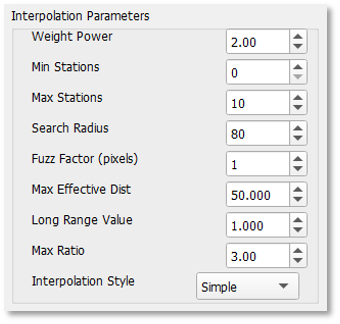
Figura 9-12 El proceso de fusión incluye una serie de parámetros que puedes modificar.
Asegúrese de comprender completamente los parámetros antes de realizar cualquier cambio; de lo contrario, deje los valores predeterminados. Vea una descripción completa de los parámetros a continuación.
Weight Power (WEIGHTPOWER): La potencia a la que se eleva la distancia inversa al calcular el peso, indica qué tan rápido disminuye la influencia de la estación a medida que aumenta la distancia desde el punto. La Figura 9-13 muestra un ejemplo de IDW con diferentes potencias.
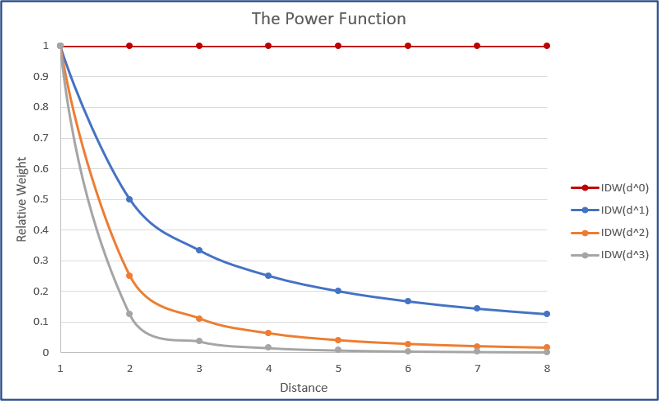
Figura 9-13 La potencia indica qué tan rápido disminuye el peso relativo a medida que aumenta la distancia.
Max Ratio (MAXRATIO): El valor máximo permitido para la relación estación/pixel. El programa calcula la relación entre los valores de la estación y el pixel en cada ubicación de hay un punto. El valor MaxRatio limita esta relación para evitar valores "descontrolados" en el proceso.
Por ejemplo, supongamos que estamos combinando un conjunto de datos de pluviómetros con una estimación de lluvia estimada de datos satelitales. En el punto de estación A, el valor de lluvia es de 10 mm, mientras que el valor del píxel en los datos raster es de 1 mm. Aunque la diferencia absoluta entre las dos estimaciones es de sólo 9 mm, la relación estación/pixel es del 10, o 1000 por ciento. La proporción de todos los puntos se interpolará y luego se multiplicará por la cuadrícula original. Supongamos que a 50 km del punto A, el píxel de la cuadrícula tenía un valor de 30 mm. Estos 30 mm se multiplicarán por un valor cercano a 10, dependiendo de las relaciones circundantes en la interpolación, y el valor resultante puede estar cercano a los 300 mm. Este error se puede limitar limitando la proporción e indicando al programa que corte cualquier proporción que supere un cierto valor (RELACIÓN MÁXIMA). De forma predeterminada, en el algoritmo se utiliza una relación de corte de 3, lo que significa que cualquier relación mayor que 3 se restablece a 3 (en el ejemplo anterior, la relación sería 3 en lugar de 10). Sin embargo, el usuario puede establecer esta proporción en cualquier valor (se puede usar un límite muy grande; por ejemplo, 100 000) si no desea tener límites en las proporciones.
Radio de búsqueda, estación mínima y estaciones máximas:
SEARCHRADIUS – describe el radio dentro del cual buscar valores de estaciones a interpolar.
MINSTNS – Número mínimo de estaciones utilizadas en la interpolación.
MAXSTNS – Número máximo de estaciones utilizadas en la interpolación.
El algoritmo de interpolación necesita valores de entrada de los campos Estaciones mínimas (MINSTNS), Estaciones máximas (MAXSTNS) y Radio de búsqueda (SEARCHRADIUS) para la estimación del valor de píxeles. En cada píxel, el algoritmo buscará las estaciones más cercanas dentro de SEARCHRADIUS desde esa ubicación de píxel y utilizará MINSTNS y MAXSTNS para limitar el número de estaciones a utilizar durante la interpolación.
Por ejemplo, supongamos que definió el número de estaciones entre 2 (MINSTNS) y 10 (MAXSTNS) que se utilizarán dentro de un radio de búsqueda de 200 km (SEARCHRADIUS). Para este caso, el algoritmo buscará las 10 estaciones más cercanas en un radio de 200 km. Si el número de estaciones encontradas es inferior a 10 estaciones, por ejemplo, 7, entonces se utilizarán esas 7 estaciones. Sin embargo, si el número de estaciones encontradas es inferior a 2, entonces a esa ubicación le faltará un valor. Por lo tanto, para BASIICS, se recomienda utilizar un valor de entrada de 0 para MINSTNS, para producir un valor en todas partes de la salida y evitar valores perdidos.
Fuzz Factor (pixels) (FUZZFACTOR): El factor difuso oculta la ubicación de la estación según el número de píxeles indicado en este campo. Un Factor Fuzz = 0 hace que el valor del píxel cerca de la estación sea lo más cercano posible al valor de la estación.
Max Effective Distance (MAXEFFECTIVEDIST): Este parámetro es la distancia máxima sobre la que tiene influencia una estación. Este parámetro solo funciona con el estilo de interpolación simple (idw_s, consulte la sección de estilo de interpolación a continuación). Es muy importante considerar las características locales de la región para elegir un valor adecuado para este parámetro. Le recomendamos probar diferentes combinaciones de valores para la distancia máxima efectiva y el radio de búsqueda para evitar el efecto localizado (ojo de buey) alrededor de la ubicación de la estación.
Interpolation Style ˅ (INTERPOLATIONALGORITHM): El programa proporciona dos algoritmos de interpolación, ponderación de distancia inversa (IDW) simple (idw_s) y ordinaria (idw_o). En el IDW ordinario, los pesos de interpolación dependen únicamente de las estaciones circundantes. El método IDW simple utiliza un campo de fondo para completar la interpolación. La cuadrícula de fondo también contribuye como peso a la rutina de interpolación, y el peso relativo de la cuadrícula de fondo aumenta al aumentar la distancia a las estaciones circundantes.
9.3.2.5. Sección 5 Región
Define Map Limits (definir límites del mapa): Le permite definir el área de interpolación (Figura 9-14). Asegúrese de que el área sea menor o igual que el conjunto de datos cuadriculado. Esta área se puede definir utilizando la extensión de una Región GeoCLIM existente u otros datos espaciales (ráster o vectoriales). Esta opción ayuda a acelerar el proceso de interpolación.
Para ejecutar el proceso de mezcla, siga los pasos a continuación:
Elija la región de la lista.
Haga clic en Next para pasar al paso 3.
Figura 9-14 Seleccione la región (cuenca, unidad administrativa, etc.) para los nuevos datos.
9.3.3. Paso 3: parámetros de fecha y configuración de guardado
Para guardar los parámetros y configuraciones de fecha, siga los pasos a continuación (Figura 9-15):
El intervalo de tiempo (por ejemplo, mes, decadias o pentadas) para el dataset ráster seleccionado se muestra automáticamente.
Seleccione el rango de tiempo From y To de los datos para combinar. El período de tiempo y el intervalo de tiempo se basan en la definición del conjunto de datos climáticos seleccionado. En este ejemplo estamos usando decadias, consulte la figura 9-17. Y estamos mezclando desde febrero (decadia 01) hasta mayo (decadia 03) de 2020.
Guarde la configuración. En este paso, puede guardar la configuración de fusión para poder abrirla desde el paso 1, editarla y reutilizarla.
Haga clic en el botón Finish para ejecutar el proceso.
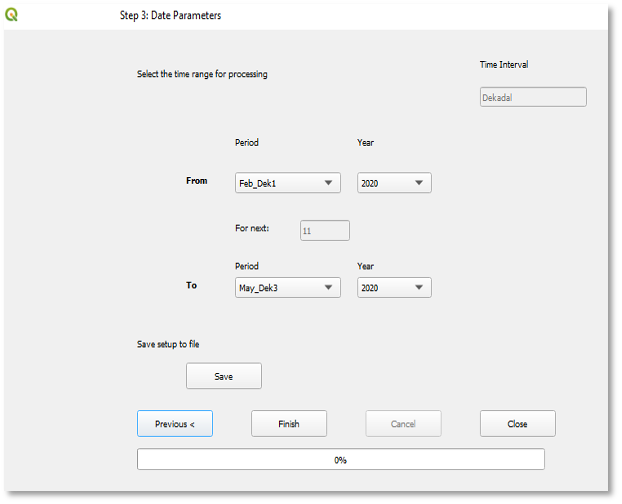
Figura 9-15 El paso 3 le permite definir el rango de tiempo para el proceso de mezcla y también puede guardar la configuración para usarla más tarde.
9.4. Salidas
El proceso de combinación crea los siguientes resultados:
Un shapefile, para cada período, que contiene todas las estaciones que se utilizaron en el proceso.
El campo combinado, para cada período. Consulte la Figura 9-16a.
Tres diagramas de dispersión que muestran la relación entre la cuadrícula original y los valores de la estación (Figura 9-16b), por ejemplo.
Un archivo CSV (Figura 9-16c) que contiene los metadatos de cada estación junto con las siguientes columnas:
Valor de la estación.
Valor ráster correspondiente.
El valor BASIICS en la ubicación de la estación.
Valor BASIICS con validación cruzada. Indica el valor BASIICS en la ubicación de la estación sin incluir esa estación específica en el proceso. Este valor responde a la pregunta de cuál sería el valor en este píxel si la estación no estuviera allí.
Sólo interpolación con validación cruzada. Valor de píxel de interpolación de estaciones únicamente, sin incluir la estación correspondiente.
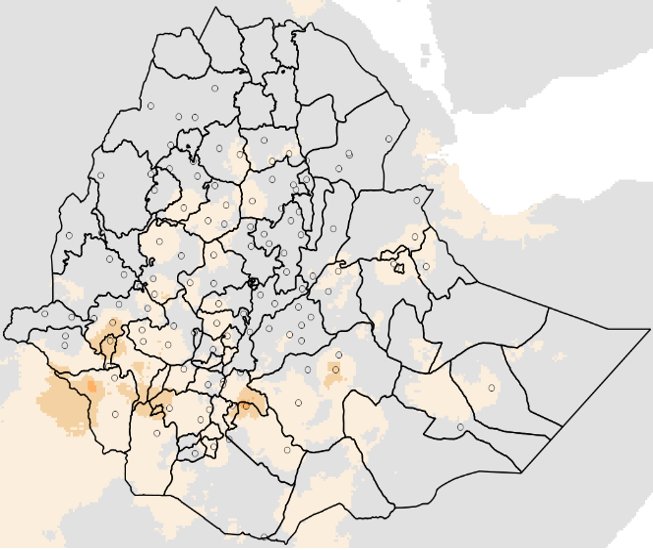
Figura 9-16a El resultado de la función BASIICS con las estaciones.
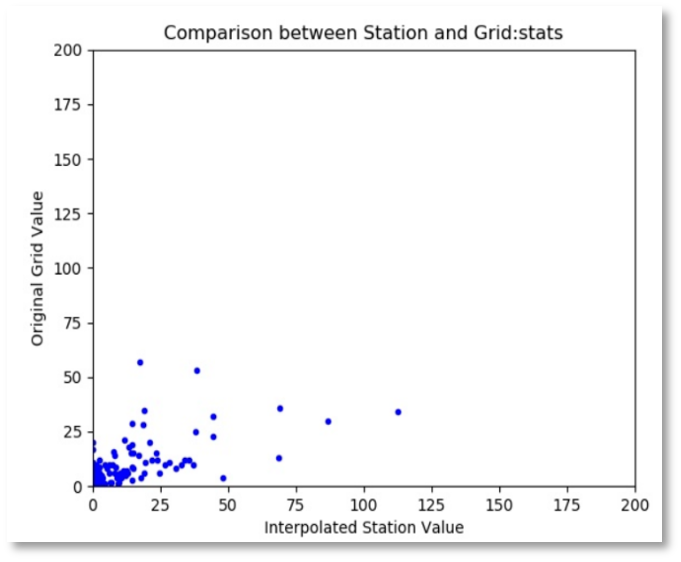
Figura 9-16b Comparación de los valores raster con los de las estaciones.
Figura 9-16c Tabla de estadística producida por la función BASIICS.